6. Estimating Epidemic models from observations#
Background: An important part of mathematical modeling is fitting models to observed data that is collected from a surveillance system. Models can serve as tools to understand the mechanics of how a pathogen moves through one or more populations, used to produce forward-looking predictions about what may happen, or studied under different interventions to evaluate their potential usefulness.
We will take the following steps to understand how to fit a compartmental model to data
Build a simulation that generates data from a SIR model. To understand how to fit a model we must first understand how a model could potentially generate our dataset.
Briefly remember how a linear regression model, \(y \sim \mathcal{N}(\mu(x), \sigma^{2})\), is fit to data.
Apply the “sum squares error” approach in (2) to our compartmental model.
Generalize (2) and (3) to other data generating mechanisms with maximum likelihood estimation.
Compartmental models can be thought of as functions from time and a set of parameters to a set of states over time or \(f(t_{0},t_{1},t_{2}\cdots,t_{T}; \theta)\). For example, we can think of the SIR model as a function that takes as input times \(t = [t_{0},t_{1},t_{2}, \cdots, t_{T}]\), two parameter values \(\theta = (\beta, \gamma)\) and then outputs the proportion of susceptibles, infected, removed over time.
where \(M\) is the matrix
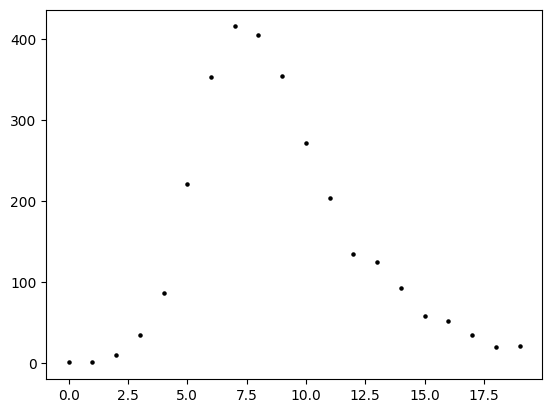
Lets assume that we collect the number of incident infected cases over the times \(t = [0,1,2,3,4,5,\cdots,10]\) and plot this as black circles (below).
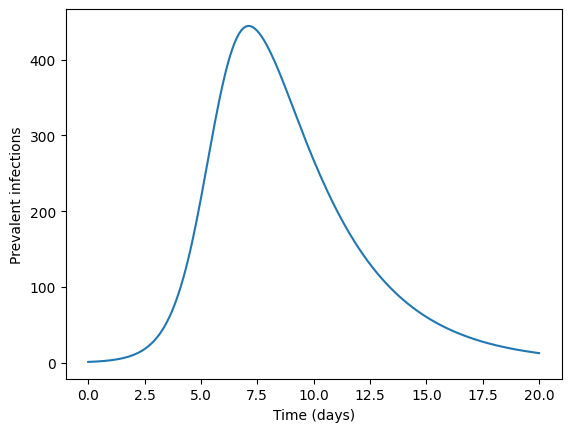
Simulating data from a SIR model—Data Generating Process#
Assume that the pathogen under study follows SIR dynamics.
Then given a vector of parameters \(\theta = (\beta, \gamma)\) and a tuple of initial condition we can estimate solutions \(S(t),I(t),R(t)\).
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import solve_ivp
n = 1000 #--number of animals in system
#--SIR differential equations
def sir(t,y, beta, gamma,n):
s,i, r, c = y
ds_dt = -beta*s*i/n
di_dt = beta*s*i/n - gamma*i
dr_dt = gamma*i
dc_dt = beta*s*i/n #--incident cases (why?)
return [ds_dt, di_dt, dr_dt, dc_dt]
#--start and end times
start,end = 0., 20
#--times that we want to return s(t), i(t), r(t)
tvals = np.arange(start,end+0.1,0.1)
#--inital conditions for s, i, r
initial_conditions = (999, 1, 0., 0)
#--parameters for the model
beta, gamma = 3./2, 1./3
#--function to return s,i,r over time
solution = solve_ivp( fun = sir
, t_span = (start,end)
, y0 = initial_conditions
, t_eval = tvals
, args = (beta, gamma,n))
prevalent_infections = solution.y[1,:]
times = solution.t
plt.plot(times,prevalent_infections)
plt.xlabel("Time (days)")
plt.ylabel("Prevalent infections")
plt.show()
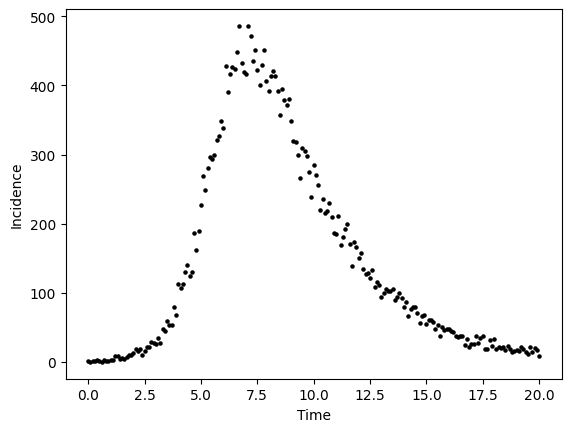
To generate data from this curve, we need to assume a data generating process. A data-generating process is a proposed algorithm for how a dataset,\(\mathcal{D}\), may have been observed. A common DGP for prevalent infections from the SIR model is to assume each data point \(y_{t}\) was produced by a corresponding random variable \(( y_{1} \sim Y_{1},y_{2} \sim Y_{2},y_{3} \sim Y_{3},\cdots,y_{T} \sim Y_{T})\)
For the below example, we assume that \(Y_{t}\) is a Poisson random variable, i.e. \(Y_{t} \sim \text{Poisson}( \lambda(t) )\) where the parameter value \(\lambda(t) = I(t)\). To implement this DGP, for \(t\) from 0,1,2,3,… to 20 we compute I(t) as we did in the above cell and then draw a value \(y_{t}\) from a Poisson distribution where \(\lambda\) equals the number of prevalent infections \(I(t)\).
#--add poisson noise
noisy_prevalent_infections = np.random.poisson(prevalent_infections)
fig,ax = plt.subplots()
ax.scatter(times, noisy_prevalent_infections, s=5,color="black")
ax.set_xlabel("Time")
ax.set_ylabel("Incidence")
plt.show()
Recap#
If we assume that this data is expected to follow SIR dynamics then we suppose two items: (i) that there exists a true SIR model and single set of parameter values \(\theta\) that are used to generate the underlying true, never observed, number of prevalent cases and (ii) that there exists a sequence of random variables that use the output from our SIR model to generate the observed number of infections over time.
We supposed above that the data above is generated by a sequence of Poisson random variables that depend on the number of incident cases at time 1, time 2, time 3, and so on
This means that different parameter values will lead to different underlying incident cases that may have generated our data.
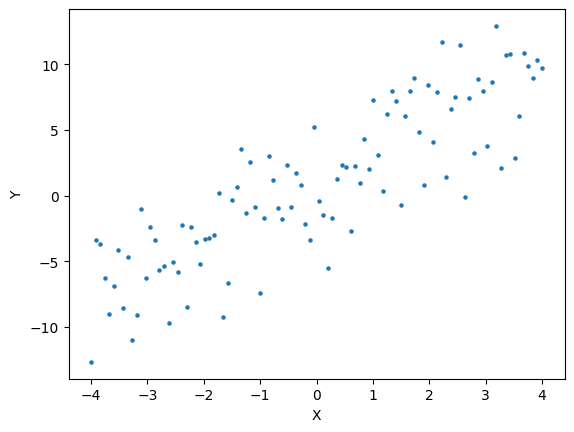
Fitting a linear regression model to data#
Suppose the following data generating process
Lets use this DGP to generate a dataset. Then we will review linear regression fitting.
# parameter values, theta = (b0,b1,sigma)
b0 = 0.5
b1 = 2
sigma = 3
x = np.linspace(-4,4,100)
y = np.random.normal( b0 + b1*x, sigma)
plt.scatter(x,y,s=5)
plt.xlabel("X")
plt.ylabel("Y")
#--easy way to build a dataset in pandas
import pandas as pd
d = pd.DataFrame({"x":x, "y":y})
print(d.head())
x y
0 -4.000000 -12.664924
1 -3.919192 -3.367601
2 -3.838384 -3.701232
3 -3.757576 -6.285753
4 -3.676768 -8.984326
Modeling Fitting#
(Parametric) model fitting is deciding, assuming our model is the true process that generated our data, which parameter values are most likely to have generated the observations that we have collected.
Least squares#
Suppose you are interested in values for a variable \(y\) called your response given values of a variable \(x\) called your A parametric model inputs a vector of values, called parameters, and returns a vector of estimated responses. One way we may evaluate how well the parameter values (\(\beta_{0}\), \(\beta_{1}\)) fits the data is with least squares.
Given \(y_{t} = \beta_{0} + \beta_{1}x_{t}\) and a set of parameter values \((\beta_{0}, \beta_{1})\), we can evaluate how well \((\beta_{0}, \beta_{1})\) fits the data by computing the average squared distance between the real data values \((y_{0},y_{1},\cdots,y_{n})\) and the model-outputted values \((\hat{y}_{0},\hat{y}_{1},\cdots,\hat{y}_{n})\).
For example, given \(\theta = (0.5,1)\) we can compute
def SSE(b0,b1,data):
yhat = b0 + b1*data.x.values
return np.mean( (yhat - data.y.values)**2 )
SSE(0.5,1,d)
np.float64(17.438305770046775)
If we can evaluate the quality of fit then we can compare two fits. If we can compare two fits then that means that we can find the best fit, the fit that is better than all others. The best fit, the one that minimizes (or maximizes depending on the metric that you use to define fit) can be found using several different computational approaches.
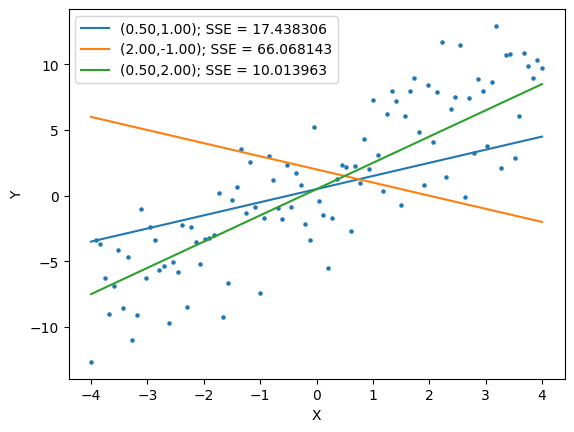
Here is an example of three fits and the associated SSEE
fig,ax = plt.subplots()
ax.scatter(x,y,s=5)
b0 = 0.5
b1 = 1.0
sse = SSE(b0,b1,d)
ax.plot(x, b0+b1*x, label="({:.2f},{:.2f}); SSE = {:f}".format(b0,b1,sse))
b0 = 2.0
b1 = -1.0
sse = SSE(b0,b1,d)
ax.plot(x, b0+b1*x, label="({:.2f},{:.2f}); SSE = {:f}".format(b0,b1,sse))
b0 = 0.5
b1 = 2.0
sse = SSE(b0,b1,d)
ax.plot(x, b0+b1*x, label="({:.2f},{:.2f}); SSE = {:f}".format(b0,b1,sse))
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
<matplotlib.legend.Legend at 0x7f1313843550>
We can find the best fit using the scipy function called minimize. What you need for the minimize function is
An objective function that inputs parameters and outputs a value that describes the fit. Smaller values indiciate better fit.
An initial guess at the nesy parameter values.
The minimize function returns the best parameter values (possibly).
from scipy.optimize import minimize
def SSE(params,data):
b0,b1 = params #--"Unroll" parameters from the variable params
yhat = b0 + b1*data.x.values #--Build our model of the expected y
return np.mean( (yhat - data.y.values)**2 ) #--Compute the SSE
results = minimize( lambda x: SSE(x,data=d), x0=np.array([1,1]) )
print(results)
message: Optimization terminated successfully.
success: True
status: 0
fun: 9.695024864616679
x: [ 8.718e-01 2.182e+00]
nit: 6
jac: [ 1.192e-07 0.000e+00]
hess_inv: [[ 5.021e-01 2.105e-04]
[ 2.105e-04 9.191e-02]]
nfev: 21
njev: 7
Lets study the four lines inside our function SSE in depth.
def SSE(params,data):This defines a function that takes two inputs:
paramsanddata.Inside the function,paramswill be accessible to us as a list of two values, our b0 and b1.Inside the function,datawill be accessible to us as a data frame of x and y values.
b0,b1 = paramsThe first value in
paramsis assigned to the variableb0and the second value in params is assigned to the variableb1.
yhat = b0 + b1*data.x.valuesCompute the expcted value for each
xvalue in our dataset. For linear regression, the expected value is \(\beta_{0} + \beta_{1}x\).
return np.mean( (yhat - data.y.values)**2 )This computes the SSE and then returns that value outside the function.
The results = minimize( lambda x: SSE(x,data=d), x0=np.array([1,1]) ) returns an object that is stored in the variable results. The optimal parameter values are stored in results under the attribute “x”.
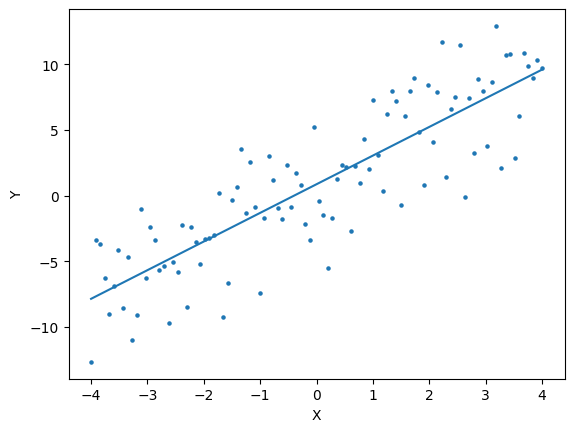
Lets plot the expected value that is “optimal”.
We can plot our results to evaluate how well the optimized function matches our intuition.
fig,ax = plt.subplots()
ax.scatter(x,y,s=5)
print(results.x)
b0,b1 = results.x
ax.plot(x, b0+b1*x, label="({:.2f},{:.2f}); SSE = {:f}".format(b0,b1,sse))
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
[0.87177107 2.18224933]
Least squares for compartmental models#
We can apply the same procedure for linear regression to compartmental models.
#--BUILD OUR DATASET
n = 1000 #--number of animals in system
#--SIR differential equations
def sir(t,y, beta, gamma,n):
s,i, r, c = y
ds_dt = -beta*s*i/n
di_dt = beta*s*i/n - gamma*i
dr_dt = gamma*i
dc_dt = beta*s*i/n #--incident cases (why?)
return [ds_dt, di_dt, dr_dt, dc_dt]
#--start and end times
start,end = 0., 20
#--times that we want to return s(t), i(t), r(t)
tvals = np.arange(start,end+0.1,0.1)
#--inital conditions for s, i, r
initial_conditions = (999, 1, 0., 0)
#--parameters for the model
beta, gamma = 3./2, 1./3
#--function to return s,i,r over time
solution = solve_ivp( fun = sir
, t_span = (start,end)
, y0 = initial_conditions
, t_eval = tvals
, args = (beta, gamma,n))
prevalent_infections = solution.y[1,:]
times = solution.t
random_noise = np.random.poisson(prevalent_infections)
data = pd.DataFrame({"times":times, "infections":random_noise})
from scipy.optimize import minimize
def SSE(params,data,n): #--lets assume n is fixed
beta,gamma = params #--"Unroll" parameters from the variable params
#--Build our SIR model of the expected y
#--SIR differential equations
def sir(t,y, beta, gamma,n):
s,i, r, c = y
ds_dt = -beta*s*i/n
di_dt = beta*s*i/n - gamma*i
dr_dt = gamma*i
dc_dt = beta*s*i/n #--incident cases (why?)
return [ds_dt, di_dt, dr_dt, dc_dt]
#--inital conditions for s, i, r Assume fixed for now
initial_conditions = (999, 1, 0., 0)
start = min(data.times)
end = max(data.times)
solution = solve_ivp( fun = sir
, t_span = (start,end)
, y0 = initial_conditions
, t_eval = data.times.values #<--evaluate our solution at all the x values we have in the data
, args = (beta, gamma,n))
prevalent_infections = solution.y[1,:]
times = solution.t
return np.mean( (prevalent_infections - data.infections.values)**2 ) #--Compute the SSE
results = minimize( lambda x: SSE(x,data=data,n=1000), x0=np.array([2,1]) )
print(results)
message: Desired error not necessarily achieved due to precision loss.
success: False
status: 2
fun: 175.80312296776376
x: [ 1.505e+00 3.299e-01]
nit: 15
jac: [ 7.248e-05 1.831e-04]
hess_inv: [[ 4.955e-08 -1.980e-12]
[-1.980e-12 5.719e-13]]
nfev: 250
njev: 76
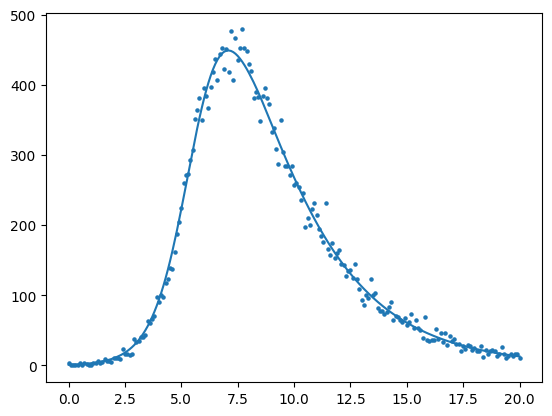
#--ESTIMATED PARAMETERS
beta,gamma = results.x
#--inital conditions for s, i, r Assume fixed for now
initial_conditions = (999, 1, 0., 0)
start = min(data.times)
end = max(data.times)
solution = solve_ivp( fun = sir
, t_span = (start,end)
, y0 = initial_conditions
, t_eval = data.times.values #<--evaluate our solution at all the x values we have in the data
, args = (beta, gamma,n))
prevalent_infections = solution.y[1,:]
times = solution.t
plt.scatter(data.times.values,data.infections.values,s=5)
plt.plot(times,prevalent_infections)
[<matplotlib.lines.Line2D at 0x7f1313754d50>]
Least squares is just a special type of maximum likelihood estimation#
Lets look at a typical, first example of maximum likelihood estimation and see that least squares is a special case. Suppose you want to model a dataset \(\mathcal{D} = (y_{1}, y_{2},y_{3},\cdots,y_{n})\) with the following model
that is, we will assume each data point was drawn from a Normal distribution with mean \(\mu\) and variance \(\sigma^{2}\). Lets go a step further and assume that we know the variance \(\sigma^{2} = 1\).
Our goal is to estimate \(\mu\). One way to develop an objective function that we can use to compare two \(\mu\) values is maximum likelihood estimation (MLE). MLE says that a \(\mu\) value is high quality if there is a high probability that this parameter value was used to generate our dataset. The probability of our dataset given a specific, single \(\mu\) value is
well this is sort of a problem. We dont know the joint probability of each of the values in our data simulataneously. Instead, lets assume that all the observations were generated independently from one another. Then the above simplifies to
This is called the likelihood function. The input is a set of parameters (in this case \(\mu\)) and the output is the probability that this parameter value helped generated the dataset.
Lets substitute p(y|\mu,\sigma^{2}) for the functional form of the Normal distribution and simplify. The Normal distribution has probability density
If we can compute the probability of a dataset with two y values, then maybe we can find a pattern that we can apply to a dataset with \(n\) values.
Looks like a pattern is forming. For \(n\) data points
How the heck do we maximize this??? Recall that \(e^{-x^{2}}\) is a bell curve peaked at zero. Therefore, the function \(e^{-x^{2}}\) is maximized when \(x=0\), and so it follows that the function \(e^{-(x-a)^{2}}\) is maximized when \(x=a\). In other words, maximizing the function \(e^{-(x-a)^{2}}\) is the same as minimizing the function \((x-a)^{2}\) (think about this for a minute, its not immediately intuitive.).
Lets apply this idea to our problem above. Maximizing the function \(\exp \left\{ -\sum_{i=1}^{n} \frac{1}{2\sigma^{2}} \left[y_{i}-\mu\right]^{2}\right\}\) is the same as minimizing the function \(\sum_{i=1}^{n} \frac{1}{2\sigma^{2}} \left[y_{i}-\mu\right]^{2}\). If we set \(\sigma^{2}=1\) then our goal is to minimize
What does this mean, though?#
This means that when we were minimizing the SSE we (implictly) assumed that our data was generated by a Normal distribution—whoa.
#--CREATE A FUNCTION CALLED NLL THAT EVALUATES POTENTIAL SOLUTIONS
from scipy.optimize import minimize
def nll(params, data):
beta,gamma = params
from scipy.stats import poisson
import numpy as np
def sir(t,y, beta, gamma):
s,i, r, c = y
ds_dt = -beta*s*i
di_dt = beta*s*i - gamma*i
dr_dt = gamma*i
dc_dt = beta*s*i #--incident cases (why?)
return [ds_dt, di_dt, dr_dt, dc_dt]
N = 1000
initial_conditions = (999./1000, 1./1000, 0., 0)
start = min(data.times)
end = max(data.times)
solution = solve_ivp( fun = sir
, t_span = (start,end)
, y0 = initial_conditions
, t_eval = data.times.values #<--evaluate our solution at all the x values we have in the data
, args = (beta, gamma))
prop_prevalent_infections = solution.y[1,:]
expected = N*prop_prevalent_infections
return -1*np.sum(poisson(expected).logpmf(data.infections.values))
#--RUN THE MODEL TO ESTIMATE PARAMETERS
import numpy as np
beta,gamma = 1.,1./2
results = minimize( lambda params: nll(params,data), x0 = np.array([beta,gamma]) )
print(results)
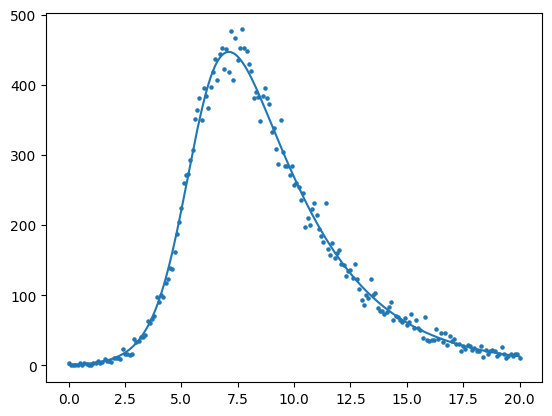
#--PLOT THE ESTIMATED SOLUTION
beta,gamma = results.x
def sir(t,y, beta, gamma):
s,i, r, c = y
ds_dt = -beta*s*i
di_dt = beta*s*i - gamma*i
dr_dt = gamma*i
dc_dt = beta*s*i #--incident cases (why?)
return [ds_dt, di_dt, dr_dt, dc_dt]
N = 1000
initial_conditions = (999./1000, 1./1000, 0., 0)
start = min(data.times)
end = max(data.times)
solution = solve_ivp( fun = sir
, t_span = (start,end)
, y0 = initial_conditions
, t_eval = data.times.values #<--evaluate our solution at all the x values we have in the data
, args = (beta, gamma))
prop_prevalent_infections = solution.y[1,:]
expected = N*prop_prevalent_infections
plt.scatter(data.times.values, data.infections.values, s=5)
plt.plot(data.times.values,expected)
message: Desired error not necessarily achieved due to precision loss.
success: False
status: 2
fun: 719.843280795448
x: [ 1.503e+00 3.304e-01]
nit: 14
jac: [ 2.350e-03 6.409e-04]
hess_inv: [[ 6.227e-07 -3.459e-06]
[-3.459e-06 2.704e-05]]
nfev: 119
njev: 36
[<matplotlib.lines.Line2D at 0x7f1312c10210>]
Homework#
We will assume a dataset \(\mathcal{D} = (y_{1},y_{2},y_{3}, \cdots, y_{t})\) was generated by an SIR model with Binomial noise. If \(Y_{i}\) has a Binomial distribution then
where we will assume our data points are fixed \(y_{1}, y_{2}, \cdots, \), the total number of people in the population, \(N\), is a fixed number, and the binomial coeffieint, \(\binom{N}{y}\), is also a fixed quantity.
Our model will assume the number of infected individuals is
where \(I_{t}\) is the proportion of infected indiviuals in the population and is generated by the following SIR model
with \(N=1000\) individuals in the population, and initial proportion of susceptible 999/1000, proportion of infected 1/1000, and proportion of removed 0/1000.
The log probability of a data point
Use the probability distribution above to please write down the (natural) log probability of a datapoint \(y\) at time \(t\) given we know the true proportion of infected \(I_{t}\), or \(\log\left[P(Y_{t}=y | I_{t})\right]\).
The log probability of a data set (\(\mathcal{D}\))
Recall that the log probability of our dataste can be written
and plug-in the log probability that you found in quesiton 1.
Because this expression will be a function of \(\beta\) and \(\gamma\), we can simplify the log probabiliy of our dataset by removing any expressions that are constant. Pleae simplify this expression as well.
Given a (\(\beta\),\(\gamma\)) compute the probability (ie the goodness of the fit)
Assume S0=0.999, I0=0.001, R0=0. Further assume N=1000 and also assume that \(\beta = 3\) and \(\gamma=1\).
Write down python code that does the following
(a) Estimates \(I(t)\) for times 1,2,3,4,5,6,7,…,20. using solve_ivp.
(b) Computes the log probability of the observed dataset below called data.
(c) Compare the log probability of the dataset for two options for \(\beta\) and \(\gamma\). The correct parameter values \(\beta = 3/2\) and \(\gamma=1/3\) and incorrect parameter value \(\beta = 2\) and \(\gamma=1\).
Please comment on the difference in probability values.
Minimize
Use the minimize function from scipy.optimize to estimate \(\beta\) and \(\gamma\) from our dataset data. Note that in order to use minimize, you must create a function that inputs a vector beta, gamma, and outputs the negative log probability (ie the smallest negative log probability is the largest positive log probability).
Dataset#
beta, gamma = 3./2, 1./3
#--SIR differential equations
def sir(t,y, beta, gamma):
s,i, r, c = y
ds_dt = -beta*s*i
di_dt = beta*s*i - gamma*i
dr_dt = gamma*i
dc_dt = beta*s*i #--incident cases (why?)
return [ds_dt, di_dt, dr_dt, dc_dt]
#--inital conditions for s, i, r Assume fixed for now
initial_conditions = (999./1000, 1./1000, 0., 0)
solution = solve_ivp( fun = sir
, t_span = (start,end)
, y0 = initial_conditions
, t_eval = np.arange(0,20,1) #<--evaluate our solution at all the x values we have in the data
, args = (beta, gamma))
prop_prevalent_infections = solution.y[1,:]
times = solution.t
y_values = np.random.binomial(1000, prop_prevalent_infections)
#--THIS IS THE DATASET YOU ARE WORKING WITH FOR HW
data = pd.DataFrame({"times":times, "y":y_values})
plt.scatter(data.times, data.y, color='k', s=5)
<matplotlib.collections.PathCollection at 0x7f1312a3ef90>