16. Bayesian Learning#
Frequentest viewpoint#
The frequentest view of statistics assumes that a set of \(n\) observations (\(o_{1},o_{2},\cdots,o_{n}\)) were generated by a sequence of corresponding \(n\) random variables (\(X_{1},X_{2},\cdots,X_{n}\)). Importantly, the frequentest viewpoint assumes that any parameters to specify the above random variables are fixed constants.
For example, we can assume that a dataset of ones and zeros \(\mathcal{D} = (0,1,0,1,1,0,1)\) was generated by a sequence of Bernoulli random variables all of which have the same parameter \(\theta=1/4\).
The uncertainty about the parameter \(\theta\) comes from the fact that we could only collect a finite number of observations. That is, frequentests assume that if you could collect an infinite number of observations then the uncertainty around \(\theta\) would become arbitrarily small.
Bayesian viewpoint#
To take a Bayesian viewpoint is to assume that there exist no parameters. Instead, “parameters” are themselves random variables that have their own inherent uncertainty. In our above example, a Bayesian viewpoint would assume that for each observation we draw a parameter value \(\theta_{1}\) from some density \(\theta \sim f_{\theta}\) and then drew a 0/1 value from a Bernoulli with that given theta value.
thetas = np.random.beta(1,1,7)
data = np.random.binomial(1,theta)
fig,axs = plt.subplots(1,2)
ax=axs[0]
ax.hist(thetas,7)
ax.set_title("Theta")
ax=axs[1]
ax.hist(data,2)
ax.set_title("Observed values")
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 1
----> 1 thetas = np.random.beta(1,1,7)
2 data = np.random.binomial(1,theta)
3
4 fig,axs = plt.subplots(1,2)
NameError: name 'np' is not defined
Bayesian Learning#
The goal of Bayesian learning (often called inference) is to estimate the probability density over parameter values. In our above example, the goal would be that given a dataset (\(\mathcal{D}\)) to learn the probability density about \(\theta\) or \(p(\theta | \mathcal{D})\) where \(\mathcal{D} = (0,1,0,1,1,0,1)\).
This inference task can be solved using Bayes theorem.
where \(p(\mathcal{D} | \theta)\) is the likelihood (from Frequentest statistics), \(p(\theta)\) is called the prior probability about \(\theta\), and \(p(\mathcal{D})\) is typically called the evidence that our model generated the observed dataset.
If we are only considering a single model then the evidence (\(p(\mathcal{D})\)) is a constant and we can write
Bayesian learning in infectious disease modeling (The goal)#
In a typical infectious disease modeling setting, we are given a time series of observations. We assume a reasonable epidemic model that could have generated this dataset, and the goal is to estimate parameters from this model. In a Bayesian setup, we are asked to estimate the probability density over our parameters.
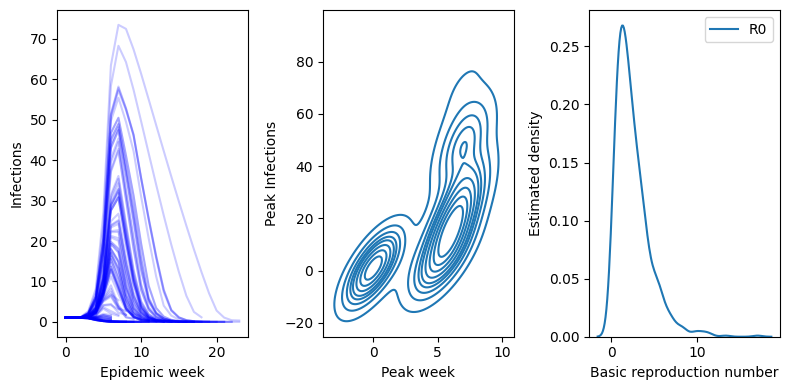
With a probability density over parameters in hand, we can compute densities over useful epidemiological quantities like the basic reproduction number, peak number number of infections, or we can forecast forward epidemiological quantities like the number of infections.
For example, we may be given a series of observed incident infections. We assume that the pathogen moving through the host population follows typical SIR dynamics. A typical Bayesian setup for this model may be
import numpy as np #--for array and matrix computations
from scipy.integrate import solve_ivp #--needed to solve the ODE system
import matplotlib.pyplot as plt #---for plotting
import pandas as pd
import seaborn as sns
def sirs(t,y,beta,gamma,n):
s,i,r = y #<- We assume that y holds the values s,i,r at each tiny time step from start to end
ds_dt = -beta*s*(i/n)
di_dt = beta*s*(i/n) - gamma*i
dr_dt = gamma*i
return [ds_dt, di_dt, dr_dt] #<-- Its our job to compute the derivatives and return them as a list
betas = np.random.gamma(2,1,800)
gammas = np.random.beta(5,1,800)
start,end = 0,15
#--set the number of S,I,R at time 0.
S0 = 100
I0 = 1
R0 = 0.
#--Compute the total number of individuls (n)
n = S0+I0+R0
initial_conditions = (S0,I0,R0) #<--Grouped initial conditions into a tuple
fig,axs = plt.subplots(1,3,figsize=(8,4))
peaks = []
for (beta,gamma,phi) in zip(betas,gammas,phis):
solution = solve_ivp( fun = sirs
, t_span = (start,end)
, y0 = initial_conditions
, args = (beta,gamma, n) )
#--Extract solutions from the object called "solution"
times = solution.t
St = solution.y[0,:] #<-first row is S
It = solution.y[1,:] #<-second row is I
Rt = solution.y[2,:] #<-third row is R
axs[0].plot(It, color="blue", alpha=0.2)
peaks.append( (np.argmax(It),np.max(It)) )
ax=axs[0]
ax.set_xlabel("Epidemic week")
ax.set_ylabel("Infections")
ax = axs[1]
peak_time,peak_value = zip(*peaks)
sns.kdeplot( pd.DataFrame({"peak_time":peak_time,"peak_value":peak_value}), x="peak_time", y="peak_value",ax=ax )
ax.set_xlabel("Peak week")
ax.set_ylabel("Peak Infections")
ax=axs[2]
sns.kdeplot( pd.DataFrame({"R0": betas/gammas }) ,ax=ax )
ax.set_xlabel("Basic reproduction number")
ax.set_ylabel("Estimated density")
fig.set_tight_layout(True)
plt.show()
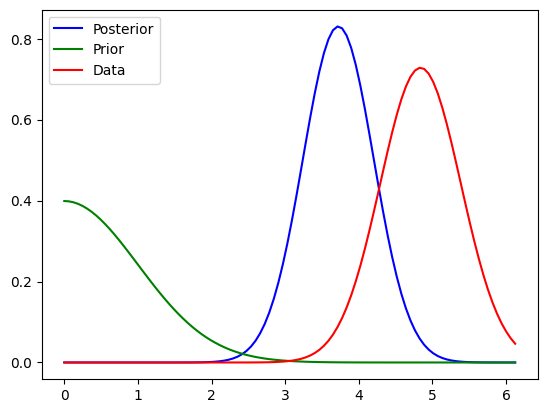
import numpy as np
import scipy.stats
n = 10
sigma2 = 3
data = np.random.normal( loc=4,scale=sigma2, size=n )
m = 0
s2 = 1
weight = ( n/sigma2 + 1/s2 )
xbar = np.mean(data)
M = ((n/sigma2)/weight)* xbar + ((1/s2)/weight)*m
fig,ax = plt.subplots()
domain = np.linspace(0,M+5*np.sqrt(weight**-1),100)
posterior_pdf = scipy.stats.norm( M,np.sqrt(weight**-1))
prior_pdf = scipy.stats.norm( 0,np.sqrt(s2))
data_pdf = scipy.stats.norm( xbar, np.sqrt(sigma2/n) )
ax.plot( domain, posterior_pdf.pdf(domain) , color="blue", label="Posterior")
ax.plot( domain, prior_pdf.pdf(domain), color="green", label="Prior" )
ax.plot( domain, data_pdf.pdf(domain), color="red",label="Data" )
ax.legend()
<matplotlib.legend.Legend at 0x10f816e90>