
Chapter 06: Bernoulli, Binomial, Poisson, Geometric#
from IPython.display import display, HTML
display(HTML("""
<style>
.callout { padding:12px 14px; border-radius:10px; margin:10px 0; }
.callout.note { background:#eff6ff; border-left:6px solid #3b82f6; }
.callout.warn { background:#fff7ed; border-left:6px solid #f97316; }
.callout.good { background:#ecfdf5; border-left:6px solid #10b981; }
.callout.bad { background:#fef2f2; border-left:6px solid #ef4444; }
</style>
"""))
display(HTML("""
<style>
/* Base callout */
.callout {
padding: 12px 14px;
border-radius: 10px;
margin: 12px 0;
line-height: 1.35;
border-left: 6px solid;
box-shadow: 0 1px 2px rgba(0,0,0,0.06);
}
/* NOTE variant */
.callout.note {
background: #eff6ff; /* light blue */
border-left-color: #3b82f6; /* blue */
}
/* Optional: title line inside */
.callout .title {
font-weight: 700;
margin-bottom: 6px;
}
</style>
"""))
Introduction#
Several probability distributions have been studied in depth. Templates like this allow us to model data generated from an experiment quickly. Random variable templates are so useful that several programming languages have optimized how to compute probabilities, expected values, and higher moments.
We will study parametric distributions for random variables. A set of parameters—constants—determine how our random variable assigns probabilities to outcomes.
Discrete Distributions#
The Bernoulli Distribution or the “this or that” distribution.#
It is often the case that we collect data that can produces one of two categories. For example, (a) we may collect whether or not patients have experienced an adverse clinical event during the course of a clinical trial. (b) Another example is whether a sampled population has , or does not have, private medical insurance. (c) In this study, researchers explored the effectiveness of an infectious disease outbreak protocol by collecting whether hospitalized patients were, or were not, part of an outbreak. A natural way to model “this or that” data is with a Bernoulli distribution.
The Bernoulli distribution assigns probabilities to a random variable whose support contains the values 0 and 1. The Bernoulli distribution has a single parameter, often denoted \(\theta\), that controls how probabilities are assigned to these two values, 0 and 1.
To communicate that a random variable \(Z\) has a Bernoulli distribution with parameter \(\theta\), we write:
The parameter \(\theta\) can take any value in the interval between 0 and 1 inclusive, or \(\theta \in [0,1]\). The allowable values that a parameter can take is called the parameter space. For the Bernoulli, the paramter space for \(\theta\) is the interval \([0,1]\).
The support of \(Z\) is \(\text{supp}(Z) = \{0,1\}\), and the probability mass function for the random variable \(Z\) is:
We can use the probability mass function to compute the expectation:
And we can use the probability mass function to compute the variance:
Example 1: Lets look at what it means to define a Bernoulli distributed random variable. Suppose we =define \(Z \sim \text{Bernoulli(0.45)}\). This implies Then:
Example 2: A clinical trial enrolls patients and follows them for one year. The clinical team wants to understand the proportion of patients that experience or do not experience an adverse event. We could model whether each patient either experiences or does not experience an adverse event using a Bernoulli distribution. Define \(Z_{i}\) as a Bernoulli-distributed random variable for the \(i^\text{th}\) patient in the study. When \(Z_{i} = 1\), the \(i^{\text{th}} \) patient experienced an adverse event; otherwise, \(Z_{i} = 0\).
from scipy import stats
p=1./4
support = np.arange(0,1+1,1)
pmf = stats.binom(1,p).pmf(support)
plt.vlines(support, len(pmf)*[0] , pmf, lw=2)
plt.scatter(support, pmf)
plt.xlabel("Values (x)")
plt.ylabel("P(X=x)")
plt.ylim(0,0.90)
plt.xticks([0,1])
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[2], line 5
1 from scipy import stats
2
3 p=1./4
4
----> 5 support = np.arange(0,1+1,1)
6 pmf = stats.binom(1,p).pmf(support)
7
8 plt.vlines(support, len(pmf)*[0] , pmf, lw=2)
NameError: name 'np' is not defined
The Binomial distribution#
A random variable \(X\) distributed Binomial\((N,\theta)\) has as support \(supp(X) = \{0,1,2,3,4,5,\cdots,N\}\), and the probability mass function is
where \(\binom{N}{x}\) is called a binomial coefficient and is defined as \(\binom{N}{x} = \frac{N!}{x!(N-x)!}\). The binomial coefficient is often read “N choose x” and counts the number of ways one can choose \(x\) items from a set of \(N\) items where the order that the \(x\) items is chosen does not matter. For example, \(\binom{10}{4}\) counts the number of ways to choose 4 items from a set of 10 items where the order we selected each of the four items does not matter.
The expected value and variance of \(X\) are
Given N observations, the binomial distribution assigns probabilities to the number of observations that experience an outcome of interest where we assume that the probability any single observation experiences the event is \(\theta\).
from scipy import stats
p=1./4
N=10
support = np.arange(0,10,1)
pmf = stats.binom(N,p).pmf(support)
plt.vlines(support, len(pmf)*[0] , pmf, lw=2)
plt.scatter(support, pmf)
plt.xlabel("Values (x)")
plt.ylabel("P(X=x)")
plt.ylim(0,0.30)
plt.show()
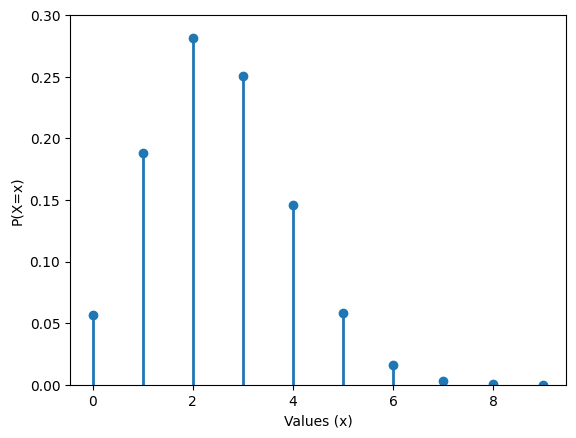
Relationship between Bernoulli and Binomial distribution#
Define the random variable \(X_{i} \sim \text{Bernoulli}(\theta)\) Then the random variable \(Y = \sum_{i=1}^{N} \sim \text{Binomial}(N,\theta)\).
Intuitively, we can think of assigning a probability to \(x\) successes and \(N-x\) failures from a Binomial distribution as equivalent to the probability of finding \(x\) 1s and \(N-x\) 0s from \(N\) Bernoulli distributions.
Lets look at how we would show that the sum of two Bernoulli distributions equals a \(\text{Bin}(2,\theta)\) distribution and then generalize.
Let \(Y = X_{1} + X_{2}\). Then the support of \(Y\) is either 0, 1, or 2.
The probability mass function for \(Y\) can be broken up into three cases By considering the sample space \(\mathcal{G} = \text{supp}(X_{1}) \times \text{supp}(X_{2}) = \{ (0,0),(1,0),(0,1),(1,1) \}\).
The sum of two Bernoulli random variables can only equal zero if both random variables take the value zero. In other words, only the element \((0,0) \in \mathcal{G}\)
The sum of two Bernoulli random variables can only equal two if both random variables take the value zero. In other words, only the element \((1,1) \in \mathcal{G}\)
The sum of two Bernoulli random variables can equal one if either the first ranomd variables equals one and the second zero, or vice-versa. In other words, the set of elements \(\{ (1,0), (0,1)\} \subset \in \mathcal{G}\)
The Poisson distribution#
If a random variable \(X\) has a Poisson distribution then the support of \(X\) is all non-negative integers or \(supp(X) = \{0,1,2,3,4,...\}\), and the probability mass function is
where \(x!\) is read “x factorial” and is defined as
For example, \(5! = (5)(4)(3)(2)(1) = 60\). The parameter space for the single parameter \(\lambda\) is all positive real numbers or \(\lambda \in (0,\infty)\).
The expected value and variance are
A random variable that follows a Poisson distribution often corresponds to an experiment where the quantity of interest is a rate. A Poisson random variable assigns probabilities to the number of occurrences of an event in a given time period.
Example The owner of a cafe wants records the number of espressos they produce each day and wants to characterize the probability they produce 0, 1, 2, etc. espressos. For one month the owner records the number of espressos produced per day and find on average that they produce 25 per day. We can model the number of espressos per day as a random variable \(X \sim Pois(25)\).
from scipy import stats
lamb = 3.5
support = np.arange(0,15,1)
pmf = stats.poisson(lamb).pmf(support)
plt.vlines(support, len(pmf)*[0] , pmf, lw=2)
plt.scatter(support, pmf)
plt.xlabel("Values (x)")
plt.ylabel("P(X=x)")
plt.ylim(0,0.25)
plt.show()
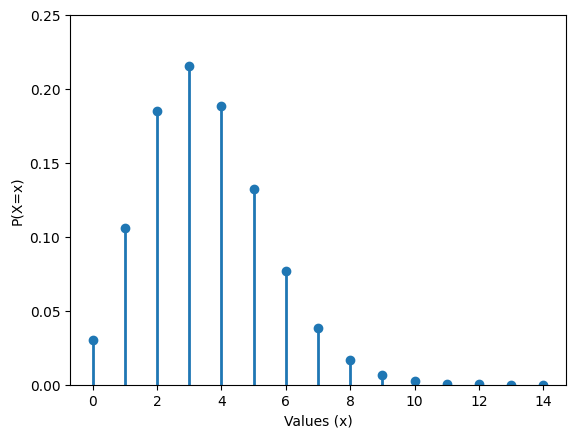
Relationship between Binomial and Poisson distribution#
Define an interval of time from 0 to \(\tau\) and suppose you wish to count the number of times some event occurs in this time interval. Divide the time interval \([0,\tau]\) into \(\delta t\) equally spaced pieces. Then there are \(N = \frac{\tau}{\delta t}\) pieces from 0 to \(\tau\).
Define a Binomial random variable \(Y \sim \text{Binomial}(N,\lambda \delta t) \) Then we can write down the probability mass function, pull apart each term, and reform the pmf to look similar to the pmf for a poisson distribution.
First we write down the pmf for \(Y\).
Next, lets expand the binomial coefficient
We know that the poisson pmf has the term \((\lambda)^{y}/y!\). Lets re-write our above pmf to look close to this term.
At some point we will ask what happens to this pmf as \(\delta t\) shrinks towards zero. When \(\delta t\) shrinks towards zero we know that the number of pieces our interval is divided into will grow towards infinity. In other words \(\delta t \to 0 \implies N \to \infty\).
Lets try to isolate out terms with \(N\) or with \(\delta t\). First we focus on the \((1-\lambda \delta t)\) term.
Lets look at the term
Because \(N = \frac{\tau}{\delta t}\) we know that \(\delta t = \frac{\tau}{N}\).
We can also work on this term \(( 1 - \lambda \delta t )^{N}\) and see that
Lets plug this in
Now let \(\delta t\) approach zero. This means that the number of pieces \(N\) from 0 to \(\tau\) will increase towards infinity.
Then the term
Not much can be done for the term
As the number of pieces goes towards infinity the size of these pieces \(\delta t\) goes to zero and so
The final term is
and in the limit this approaches an exponential function (see the mathematical aside below if interested in why this limit approaches the exponential function).
This mean then that the probability mass function for \(Y\) converges to the function
In other words, the distribution of the random variable \(Y\) converges to a Poisson distribution with parameter \(\lambda \tau\).
Lets look at an example where we may start with a Binomial distribution but instead decide that the Poisson distribution, while an approximation, is good enough.
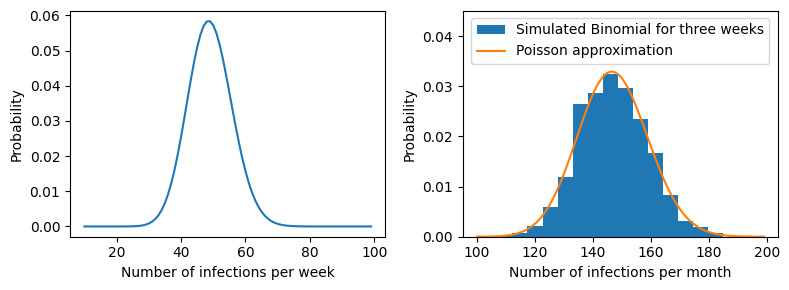
Example Suppose we wish to study the number of infections per month for a seasonal infectious agent during the “off-season”. From lab reports we find that there are 1000 individuals who are susceptible to infection. We find further that the probability of infection is a constant \(0.05\) per week and it is likely that \(20\) individuals are currently infected.
We decide to model this as a Binomial distribution with \(N=980\) and probability \(p=0.05\). Then our probability mass function looks like
from scipy import stats
import numpy as np
fig, axs = plt.subplots(1,2, figsize=(8,3))
ax = axs[0]
#--first we will display the pmf for the Binomial corresponding to infections per week
support = np.arange(10,100)
Y = stats.binom( n=980, p = 0.05 )
ax.plot(support, Y.pmf(support))
ax.set_ylabel("Probability")
ax.set_xlabel("Number of infections per week")
#--simulation of three binomial distributions added up.
#--In other words, the total number of infections per month.
infect_per_month = []
for nsim in range(2000):
threeweeks = np.random.binomial(980,0.05,size=3)
threeweeks = sum(threeweeks)
infect_per_month.append(threeweeks)
ax = axs[1]
ax.hist(infect_per_month, 15, density=True, label="Simulated Binomial for three weeks")
#--Then we will display the pmf for the Poisson corresponding to infections per week ( 980 times 0.05 per week times three weeks )
support = np.arange(100,200)
Z = stats.poisson( 980*0.05*(3./1) )
ax.plot(support, Z.pmf(support), label="Poisson approximation")
ax.set_ylabel("Probability")
ax.set_xlabel("Number of infections per month")
ax.set_ylim(0,0.045)
ax.legend(loc="upper center")
fig.set_tight_layout(True)
Mathematical aside
The goal of our mathematical aside is to show that \( \lim_{N \to \infty} (1+\frac{x}{N})^{N} = e^{x}\). If we can show that then we can see that
One approach is to evaluate the above sequence
for the first couple of values and observe a pattern. For \(N=2\), we find
The above formula is called the Binomial expansion. The Binomial expansion says
We can apply this rule for our problem. Our “\(y\)” is the value \(1\) and our “\(x\)” is the value \(\frac{x}{N}\).
Lets see if we can make sense of the first few terms and find a pattern.
It looks like we will end up with terms like \(\frac{x^{n}}{n!}\) and then a product of terms like \( (1-1/N)(1-2/N)(1-3/N)\) etc. Because each of these terms goes to one as \(N\) goes to infinity their product will go to one too. Then we’re left with
This is the series expansion for \(e^{x}\). In other words
Relationship between Bernoulli and Poisson distribution#
Again, suppose we ask to compute the probability that a specific number of event occurs in an interval \([0,\tau]\). We may decide to model the number of events that occur in this interval using a Poisson random variable. For example, we can define a random variable \(X \sim \text{Pois}( \lambda \tau )\). Where \(\lambda\) is a rate (number of occurrences divided by time) and \(\tau\) is a time interval.
The pmf for \(X\) is
and the probability of no occurrences is
and the probability of a single occurrence in this interval is
Again, partition this interval from 0 to \(\tau\) into small pieces of length \(\delta t\). Then the number of occurrences in the interval of length \(\delta t\) is
where the random variable \(Y_{1}\) is the random variable corresponding to the first interval \([0,\delta t]\). But if we assume that \(\delta t\) is very small, we can approximate the probability assigned to zero occurrences and one occurrence. We will see that this approximation lends itself to defining a new random variable that is distributed Bernoulli.
We know that the exponential function has a series representation
However, if \(\delta t\) is extremely small then \((\delta t)^{2}\) is so small it can be excluded. That is
Lets plug-in this approximation for our random variable \(Y_{1}\).
The probability of any occurrences beyond one is so small that is negligible as well.
We can define a random variable \(Z \sim \text{Bernoulli}( \lambda \delta t )\) that represents this approximation. That is, if we cut the interval \([0,\tau]\) into \(N\) pieces of length \(\delta t\) then we can define \(N\) Bernoulli random variables with parameter \(\lambda \delta t\) and
interval = (0,10)
interval = interval[1] - interval[0]
deltat = 1./20
rate = 5
bern_approx = []
for nsim in range(2000):
s = 0 #<--Sum of bernoullis
for _ in range( int(interval/deltat) ):
s = s+ np.random.binomial(1, deltat*(rate) )
bern_approx.append(s)
plt.hist(bern_approx,15,density=True)
support = np.arange(30,70)
Y = stats.poisson( rate*interval)
plt.plot( support, Y.pmf(support) )
[<matplotlib.lines.Line2D at 0x117656490>]
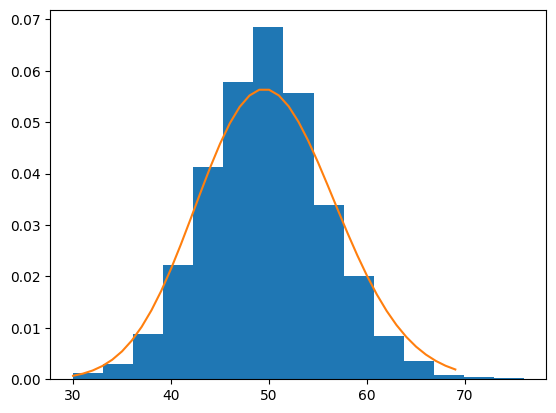
Geometric random variable#
A geometric random variable measures the number of trials until a “success”, where success is a (purposely) abstract term. You could use a geometric random variable to assess the probability until a patient experiences a stroke or time until a factory light bulb burns out.
The probability mass function for a random variable, \(Y\), with a geometric distribution is
The support for this random variable is all non-negative integers \(supp(Y) = \{0,1,2,3,4,5,\cdots\}\). The expected value and variance are
Example Suppose we wish to measure the number of days until a patient enrolled in a clinical trial experience an adverse event. From previous data, we estimate that one any day the probability a patient experiences an adverse event is 0.20. Then the probability assigned to the number of days until an adverse event can be represented by
and we would expect that \(\frac{1}{0.20}=5\) days will pass until an adverse event.
Instead of measuring the number of trials until success. You could measure on which trial a success occurs. This too has a geometric distribution
from scipy import stats
p = 1./2
support = np.arange(1,10,1)
pmf = stats.geom(1./2).pmf(support)
plt.vlines(support, len(pmf)*[0] , pmf, lw=2)
plt.scatter(support, pmf)
plt.xlabel("Values (x)")
plt.ylabel("P(X=x)")
plt.ylim(0,0.6)
plt.show()
Exponential random variable#
A Exponential random variable measures time until a “success” just like a gemoetric random variable. However, the exponential a random variable with the exponential distribution is defined over the continuum from zero to infinity \([0,\infty)\)
Like the geometric, you could use an exponential random variable to assess the probability until a patient experiences a stroke or time until a factory light bulb burns out.
The probability density function for a random variable, \(Y\), with a exponential distribution is
The support for this random variable is \(supp(Y) = [0,\infty)\). The expected value and variance are
The parameter \(\lambda \in [0,\infty]\) is the rate at which events occur, similar to the rate that was discussed above for the Poisson random variable.
An important property of the exponential density is the memoryless property. A random variable, X, is memoryless if
In other words, for the exponential distribution, the time until the next event does not depend on any previously elapsed times.
For example, suppose we tracked patients until infection with a pathogen. We model the time until infection as \(X \sim \text{Exp}(1/5)\). Then the probability that a patient is infected within 4 days equals
However, if we have a followed a patient for 10 days and ask “whats the probability that they are infected within 14 days?” the answer is the same.
The fact that we followed the patient for ten days is immaterial. This is an illustration of the memoryless property.
Example Suppose patients undergo a minor elective surgery and we wish to characterize the time until discharge from the hospital. We can characterize discharge times with a random variable \(H \sim \text{Exp}(\lambda)\) From hospital records we estimate that hospital discharges \(\lambda=3\) patienter per day. Then we can expect that the average number of days spent at the hospital is
approximately 0.33 days or \( 0.33 \text{ days} \times \frac{24 \text{hours}}{1 \text{day}}\) = 7.9 hours.
from scipy import stats
support = np.linspace(0,2,100)
pdf = stats.expon(scale=1./3).pdf(support)
plt.plot(support, pdf, lw=2)
plt.fill_between(support, [0]*len(pdf), pdf)
plt.xlabel("Values (x)")
plt.ylabel("$f_{X}(x)$")
plt.ylim(0,3)
plt.show()
Relationship between Geometric and Exponential distribution#
Suppose we wish to define a continuous random variable with support \([0,\infty)\) that has similar properties to a random variable with the geometric density. That is, we assume that there exists a random variable with probability density \(f_{X}(x)\) such that values in the support represent times until a specific event of interest. Instead of a probability that an event occurs at any given trial we assume that the probability assigned to when an event occurs follows a rate \(\lambda\).
A reasonable place to begin would be ask “can i assign a probability to an event taking place before time \(\tau\)” (and after time zero) using a geometric random variable?
One thought would be to partition the interval \([0,\tau]\) into pieces of length \(\delta x\), denote a geometric random variable \(X\), and assess the probability that \(X\) equals a value corresponding to \(\tau\).
Below is an example of splitting the interval into 10 pieces of length \(\delta x = \tau/10\).
0 [———-|———-|———-|———-|———-|———-|———-|———-|———-|———-] \(\tau\)
In other words, if we choose an interval of length \(\delta x\) then we partition our interval into \(\tau/\delta x\) pieces. The next approximation we need is the relationship we found between the Poisson and Bernoulli. If we are given a rate \(\lambda\) then we know, that for a small interval \(\delta x\), the product \(\lambda \delta x\) is equal to a probability.
Lets build our random variable
For a sufficiently small choice \(\delta x\) we find that our density is
given that \(\lim_{\delta x \to 0} (1-\lambda \delta x)^{\tau/\delta x} = e^{-\lambda x}\). This is the probability density function for the Geometric random variable described above. In some sense, the exponential is a the continuous equivalent of the geometric density.
Homework#
Let \(X \sim \text{Bernoulli}(0.2)\)
P(X=0) = ?
P(X=1) = ?
Please compute \(\mathbb{E}(X)\)
Please compute \(V(X)\)
Define the \(supp(X)\)
Let \(Y \sim \text{Bernoulli}(\theta)\), and show that \(P(Y=1) = \mathbb{E}(Y)\)
Let \(Y \sim \text{Bernoulli}(\theta)\), and show that \(V(Y) \leq \mathbb{E}(Y)\)
Let \(Y \sim \text{Bernoulli}(\theta)\), and let \(Z\) be the following function of \(Y\):
(146)#\[\begin{align} Z(y) = \begin{cases} 1 & \text{ if } y = 0\\ 0 & \text{ if } y = 1 \end{cases} \end{align}\]What probability distribution does \(Z\) follow and why?
A new vaccine for a contagious disease is tested, and the probability that a vaccinated person does not get infected upon exposure is 0.9. If a person is vaccinated and exposed to the disease, what is the probability that they:
Get infected?
Do not get infected?
Design an experiment (short description) and define a random variable \(Y\) that may follow a geometric distribution. In the context of your experiment, how would you communicate \(\mathbb{E}(Y)\) to another without statistical expertise?
A rapid test for a certain virus correctly identifies an infected patient 95% of the time (sensitivity) and correctly identifies a non-infected patient 98% of the time (specificity). If a patient is randomly tested, what is the probability that:
a) The test is positive given that the patient is infected?
b) The test is negative given that the patient is not infected?Define a random variable \(R\) with a binomial distribution \((R \sim \text{Bin}(10,0.2))\).
Compute \(\mathbb{E}(R)\)
Compute \(V(R)\)
Describe to someone who may not have statistical expertise what \(P(R=3)\) means? Be sure to include assumptions about the Binomial distribution and how the parameters \(N,\theta\) relate to this probability.
For what value of \(\theta\) is \(V(R)\) the highest? Why does this make sense intuitively?
In a town where 10% of the population is susceptible to a new flu strain, 15 people are randomly selected. Let X be the number of susceptible individuals in this group. Compute:
a) The probability that exactly 3 people are susceptible.
b) The probability that at most 2 people are susceptible.
c) The expected number of susceptible individuals.A new medication causes mild side effects in 20% of patients. If 8 patients take the medication, what is the probability that:
a) Exactly 2 patients experience side effects?
b) More than 3 patients experience side effects?Suppose \(Y \sim \text{Pois}(2)\)
Compute \(P(Y=2)\)
Compute \(P(Y \leq 2)\)
Compute \(P(Y > 2)\)
\(X \sim \mathcal{N}(\mu, \sigma^{2}) \)
Let \(Y = X - \mu\). What is the distribution of \(Y\)?
Let \(Z = Y/\sigma\). What is the distribution of \(Z\)?
Compute \(P(Z = 0)\)
Suppose we define a new random variable \(W\) with support \(supp(W) = [0,1]\) and probability density function
(147)#\[\begin{align} f_{W}(w) = 2w \end{align}\]Compute \(P(W < 1/2) = \int_{0}^{1/2} f_{W}(w)\; dw\)
Compute \(P(W < 1) = \int_{0}^{1} f_{W}(w)\; dw\)
Let \(X\) be a continuous random variable. Is \(P(X \leq x) = P(X < x)\)? Why or why not?
The number of patients arriving at a hospital’s emergency room follows a Poisson distribution with an average of 5 arrivals per hour.
What is the probability that exactly 3 patients arrive in the next hour?
What is the probability that at least 6 patients arrive in the next hour?
A hospital sees an average of 2 cases per year of a rare disease. Assuming a Poisson process, compute the probability that:
No cases are reported in a given year.
At least one case is reported in a given year.
A clinic tests individuals for a disease where 10% of tests come back positive. If patients are tested one at a time, what is the probability that:
The first positive test occurs on the 3rd test?
The first positive test occurs before the 5th test?
A new drug has a 5% probability of causing a mild side effect in a patient. If patients are monitored one at a time, find:
a) The probability that the first patient experiencing a side effect is the 4th patient tested.
b) The expected number of patients who will take the drug before the first side effect is observed.A hospital receives on average 3 critically ill patients per day who require intensive care. Suppose ICU capacity is 4 beds patient arrivals follow a Poisson distribution.
a) What is the probability that the ICU will reach full capacity in a day?
b) What is the probability that at least one bed remains empty by the end of the day?In a hospital ward, the arrival of new flu cases follows a Poisson distribution with an average rate of 5 cases per day (i.e., \(\lambda = 5 \) cases per day).
Compute the probability that exactly one new flu case occurs in a given hour.
Compute the probability that no new flu cases occur in a given hour.
If the hospital has only 2 isolation beds left, what is the probability that both beds remain empty after the next 12 hours? Hint: Use the Binomial distribution—this will help.
The time between arrivals of patients to an emergency room follows an exponential distribution with an average arrival rate of 6 patients per hour.
What is the probability that the next patient arrives within 5 minutes?
What is the probability that the next patient arrives after 15 minutes?
What is the expected time between arrivals?
For a continuous random variable, \(X\), the median is the value \(m\) such that \( \int_{\infty}^{m} f_{X}(x) \; dx = 0.50\).
Please compute an expression for the median for \(X\) if \(X \sim \text{Exp}(\lambda)\)
In a flu outbreak, the time until a susceptible person gets infected is exponentially distributed with rate \(\lambda = 1/10\) per day.
What is the probability that a person becomes infected within 3 days?
What is the median time to infection?
If a person hasn’t been infected for 10 days, what’s the probability they’ll last another 5 days uninfected?
Please follow the below steps to show that a exponentially distributed random variable \(Y\) is memoryless.
Write down the memoryless property \(P( Y>s+t | Y>s )\) and show that \(P( Y>s+t | Y>s ) = \frac{P(Y > s+t) }{ P(Y>s) }\)
For a given value \(y\), compute an expression for \(P(Y>y) = \int_{y}^{\infty} \lambda e^{-\lambda y} \; dy \)
Use the expression in (2) to show that \(\frac{P(Y > s+t) }{ P(Y>s) } = P(Y>t)\)
The time between ambulance dispatches in a city follows an exponential distribution with expected value equal to 10 minutes.
What is the probability that the next ambulance dispatch occurs in less than 6 minutes?
What is the probability the time between dispatches is more than 15 minutes?
If 2 minutes have already passed, what’s the probability the dispatch will occur in the next 5 minutes?